The Problem
Reliability of Payment Infrastructure
The US and EU banks still run payment systems software that dates back to the 1970s and 1990s, respectively which are on-premise systems and incur high maintenance costs. And the last decade witnessed bounds in enhancing developer experience and accessibility to start accepting payments, primarily led by the new-age fintech. But this has led to newer problems.
- Numerous thin layers were built on legacy infrastructure, resulting in poor reliability and a lack of visibility on the underlying layers.
- Higher payment processing costs for merchants; more the layers, more the cost.
- Lot of minor incidents (latency spikes, feature unavailability) occurring regularly on these thin layers could create significant negative business impact for merchants in the long run.
A reliable payment infrastructure assuring 100% availability that businesses can trust, and its accessibility to the large population of small and medium high-growth businesses is a pertinent problem.
Payment integrations are expensive to build and maintain
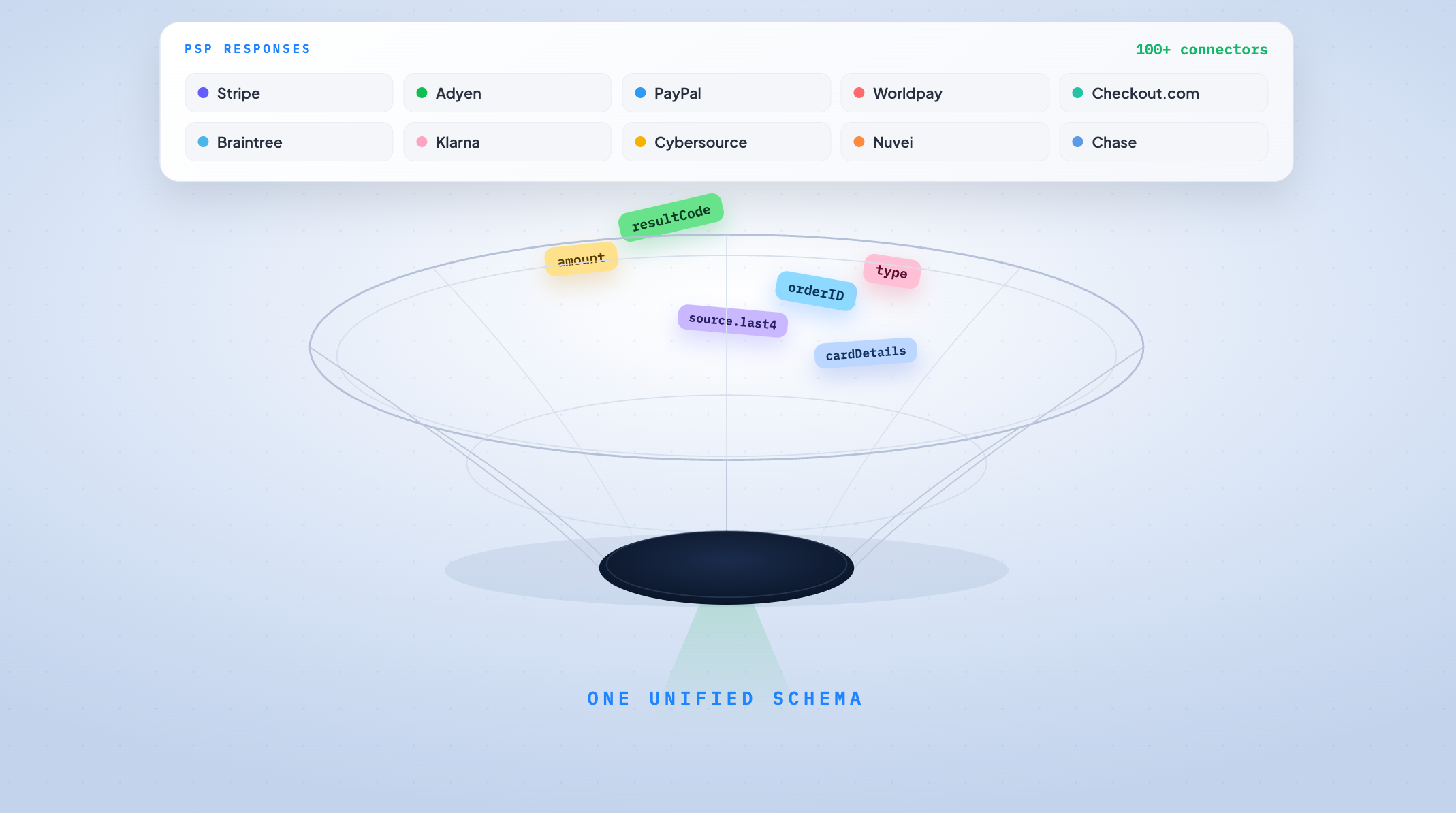
Businesses need to integrate and maintain multiple payment processors for various reasons.
- To eliminate a single point of failure in payments infrastructure.
- Provide locally accepted payment methods and new-age payment methods for customers.
- Improve authorization rates and reduce the cost of processing by ensuring healthy competition among multiple payment partners.
However, integrations involve a high quantum of data transformations to be executed, which result in incorrect data mappings, error-prone validations, and run-time errors, making it expensive to build and maintain.
Performance and Efficiency issues
Transactional systems, by nature, require high I/O throughput, super-fast data parsing, and speedy encryption and decryption. Therefore, any payment infrastructure solutions designed without sufficient attention to these needs would either result in a high cost or poor performance.
To solve these problems we built hyperswitch - an open, high-performance payment switch that is lightweight, reliable, and extensible to numerous payment processors.
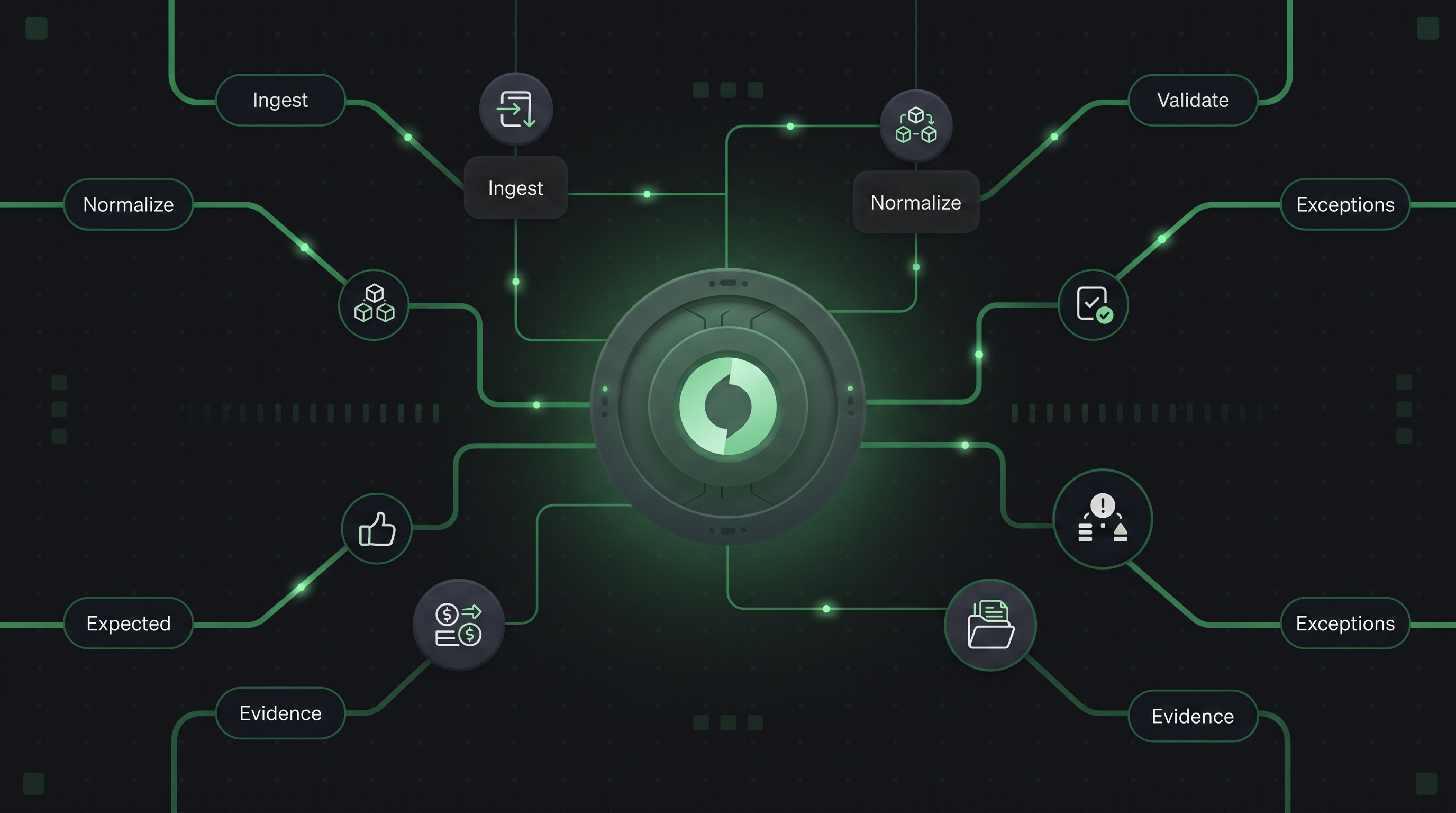
Key components of Hyperswitch
At high level, Hyperswitch has three major architectural components - Core, Connector, and Storage.
Hyperswitch Architecture

1. Core
The "Core" is the unifying layer of Hyperswitch which houses the business logic of payment processing use cases. It accepts payment requests, authenticates requests, and executes algorithms to make an optimal choice of payment processor.
2. Connectors
The "Connector" module comprises all the payment processor integrations. It does the heavy lifting of transforming the payments data into a format required by the payment processor, triggers API requests to the respective endpoint, interprets the response, and provides the final message back to the Core.
This module is constructed as a stateless service and hence fully decoupled from the Storage layer. It works for the Core to communicate with the diverse payment processor integrations and helps separate the detail-oriented data transformation layer from the Core.
The Core communicates to and fro with Connector through a standard interface abstracted to carry the payment use case and respective payment data.
3. Storage
Persistence with consistency is quite crucial for a transactional system like Hyperswitch. However, the storage layer should not become a bottleneck for a high-performance application. The critical path of a payment lifecycle primarily characterizes high-frequency read and write (lasting for a few minutes), post which it is high-frequency read and low-frequency write (lasting up to 6 months).
Hence, to ensure a high-performance system for processing peak transaction volumes, the storage is further divided into three sub-parts:
- SQL storage for ensuring persistence and consistency
- In-memory key-value store to debottleneck the SQL storage by exposing data essential for high-frequency read-write operations.
- A drainer to stream and execute the SQL read-write queries onto the SQL storage in a steady manner
Benefits
1. High Reliability
The database becomes the bottleneck for scaled transactional systems. However, with Hyperswitch's approach to storage, the database is not a bottleneck anymore. The benefits from a reliability perspective are:
- We can support a high number of concurrent connections (~ 65,000) and will be able to handle any unusual traffic spikes.
- It is easy to horizontally scale the application without any downtime.
- Sharding happens out of the box since we have designed our data model for supporting key-value store.
- Above all, the Master Database could be shut down for maintenance tuning without any service downtime.
2. Highly performant
The problems to be solved for high performance were efficient JSON parsing and concurrent system with minimal resource footprint. In addition, we needed low-level control with the promised high-level memory safety promise. Hence, we chose a low-level systems programming language - Rust, which provides performance out of the box and is far better than interpreted languages.
Hyperswitch is tuned to deliver up to 250 requests per second at 80% CPU on a single-core processor. We can process up to 60 payments per second from a single-core processor.
3. Scaling and maintaining integrations are easier
We leverage Rust's strongly typed system to ensure that any data transformation errors are caught during compile time. As a result, the code that compiles is as good as running on production.
Our domain-based type system helps us write lesser and more readable code with lesser technical debt.
And finally, since the connectors (or integrations) are decoupled from the storage layer, it provides us with great power to scale our integrations in an agile and efficient manner.